*사용된 모든 영문 image의 출처는 cs231n 강의 자료입니다.*
<Topic Modeling>
1. Bag-of-Words Encoding of Text Documents
2. Topic Modeling
Bag-of-Words Encoding of Text Documents
* Structured data / Unstructured data → image, sentence
Bag-of-Words vector
Document 1 = 'John likes movies. Mary likes too.'
Document 2 = 'John also likes football.'
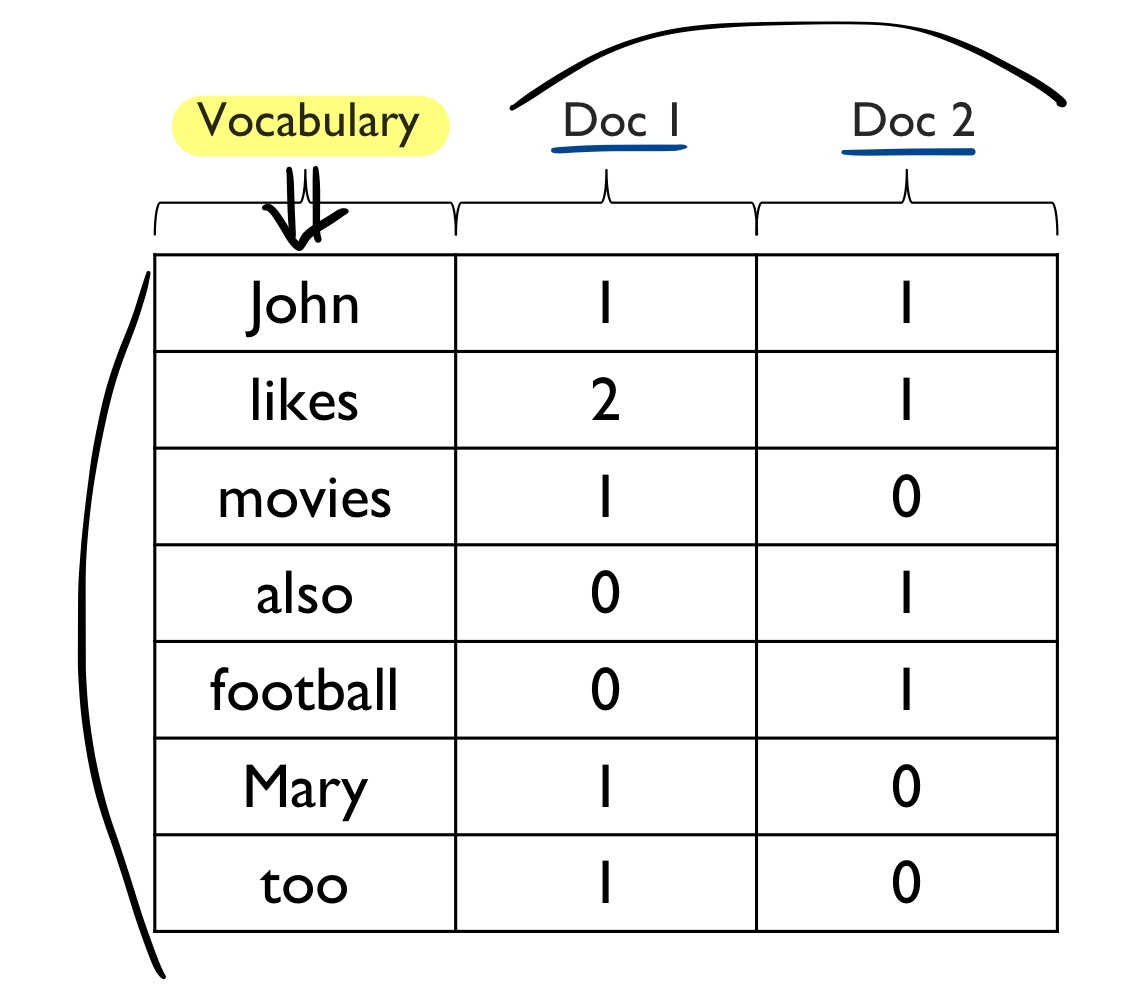
Vocabulary = 모든 word의 집합
Term-Document Matrix = Document 별 각 word의 수를 Matrix로 표현
→ Bag-of-words 기반의 word 수 표현
Bag-of-Words Loss

- Term-Document Matrix를 Topic vector와 각 coefficient weight의 weighted combination으로 표현
- weighted combination을 한 matrix로 표현하여 원래 TDM과의 loss 계산
- Loss는 Frobenius norm 사용하여 각 topic의 weight와 topic vector을 train
Topic Modeling
Topic
| Topic을 keyword의 probability distribution으로 표현 | Topic을 Keyword의 weighted combination으로도 표현 |
| 다른 keyword는 다른 probability를 가진다. | 다른 keyword는 다른 importance score를 가진다. |
Topic Modeling
- Document set에서 나와 topic set을 추출
- Document를 topic 상의 probability distribution으로 표현
- Document를 topic 상의 weighted combination으로 표현
- Keyword cluster / Document Cluster

Topic Linear Discriminant Analysis
- 100-topic LDA on 16,000 documents
- Remove some standard stopwords
- Top keywords for some p(w|z)

Result

→ Document를 각 score에 맞는 topic에 modeling
'NLP' 카테고리의 다른 글
| Character-level Language Model (0) | 2022.06.21 |
|---|---|
| Word Embedding - Word2Vec, Glove, Doc2Vec (0) | 2022.06.20 |
| Bag-of-Words (0) | 2022.06.16 |
| NLP overview (0) | 2022.06.16 |
| NLP 이해하기 (0) | 2022.04.07 |


