RNN과 LSTM과 다르게 Transformer는 input X가 병렬 처리되어 투입된다.
병렬 구조의 투입은 연산 속도가 향상되고 long-term dependency 문제를 해결할 수 있지만, sentence의 sequential 한 정보가 제거된다는 치명적인 단점이 있다. 따라서, Transformer에서는 Input Embedding에 Positional Encoding이라는 위치 정보 Matrix를 더하여 새롭게 계산된 Matrix를 첫 번째 encoder의 input으로 투입한다.

Positional encoding 계산 방법에는 다양한 advanced 된 방법이 있지만, 처음 Transformer 구조가 소개된 "Attention is All You Need" 논문에서 사용된 Sinusoidal Positional의 계산 과정을 직접 작성해보았다.
Sinusodial function은 해당 position의 embedding인 i가 짝수일 때와 홀수일 때로 나누어 계산하여 matrix를 산출한다. Sinusodial Positional Encoding에 대한 자세한 내용은 'Transformer' 게시글에 적어놨으니 이번 게시글에서는 간단한 계산 과정만 업로드한다.
글씨 개판 주의!

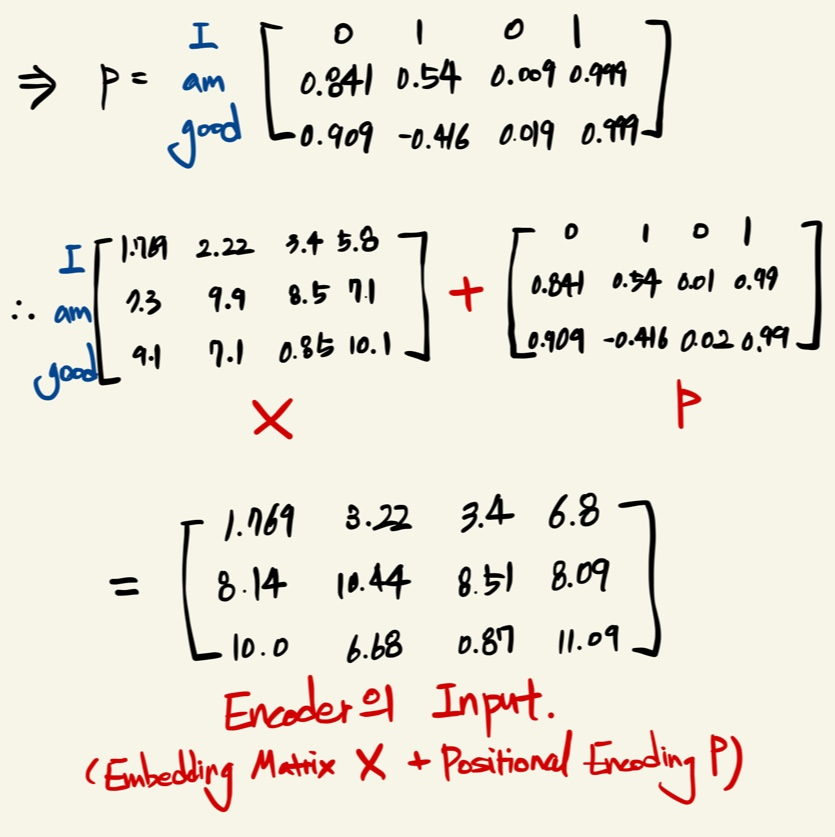
이런 식으로 Embedding Matrix X에 대한 Positional Encoding Matrix를 구하여 둘을 합산한 Matrix를
Encoder의 Input으로 투입시키면 된다.
'NLP' 카테고리의 다른 글
| GPT (0) | 2022.07.05 |
|---|---|
| BERT (0) | 2022.07.01 |
| Transformer (0) | 2022.06.30 |
| Tokenization (0) | 2022.06.28 |
| Basic Regular expression 연습 (0) | 2022.06.27 |



