BERT
LM preview
- Language Model은 단어 sequence에 확률을 할당하는 model
- 가장 자연스러운 단어 sequence를 찾는 model
- LM이 이전 word가 주어졌을 때, 다음 word를 predict
- Language Modeling: 주어진 word들로부터 아직 모르는 word를 predict하는 작업
Pre-training
Initialize part of the model with networks trained using unsupervised learning
→ Sepatrate model을 training 해야 한다는 단점 有
Language understanding by generative pre-training
GPT Ⅰ

- 12-layer decoder-only transformer
- 12 head / 768 dimensional states
- GeLU activation unit

BERT
(Pre-training of Deep Bidirectional Transformers for Language Understanding)

- Masked Language Modeling tasks 사용
- Large-scale data & Large-scale model 사용
BERT 이전 model들에서 Masked LM의 문제점
Language Model이 left context 혹은 right context만 사용
→ But, language understanding은 bi-directional

f use bidirectional langauge model??
→ Word들이 'see themselves' 해버려서 train이 안 된다. (= cheating ..)
Pretraining tasks in BERT
Masked Language Model (MLM)
- Input token을 random하게 masking한 후, model이 masked된 token을 predict
- Word의 15%를 masking한 후 predict
· 80%: [MASK] token
· 10%: Random word
· 10%: Same word
Next Sentence Prediction (NSP)
- 두 sentence가 proceed한지, 아니면 random sentence인지 predict
- <CLS> token의 결과로 출력


BERT Architecture
- BERT BASE: L = 12, H = 768, A = 12
- BERT LARGE: L = 24, H = 1024, A = 16
(L = self-attention의 bloock(layer) 수,
H = Hidden state vector의 dimension (모든 layer에서 동일),
A = Multi-head attention에서 head의 수)
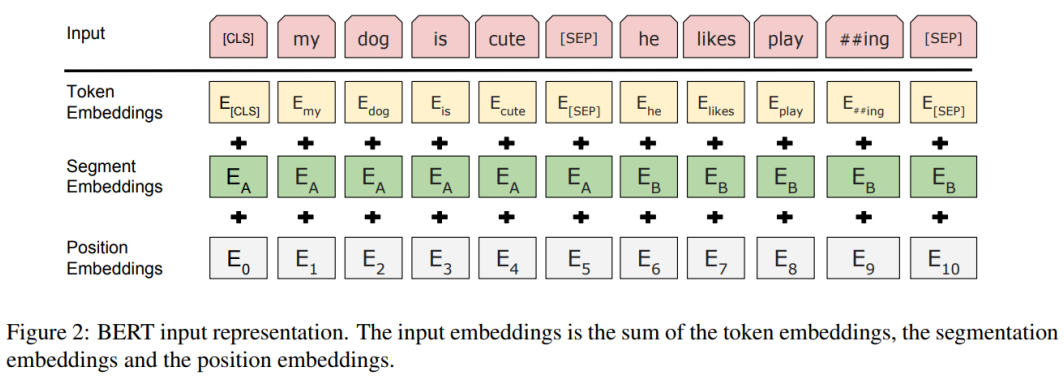
BERT Input Representation
· WordPiece embeddings (30,000 WordPiece)
· Learned positional embedding
(→ 참고로, Transformer에서는 positional embedding을 learn하나 안 하나 별 차이가 없다고 한다.)
· [CLS] - Classification embedding
· [SEP] - Packed sentence embedding
· Segment Embedding
BERT pre-training Tasks
· Masked LM
· Next Sentence Prediction
BERT fine-tuning process
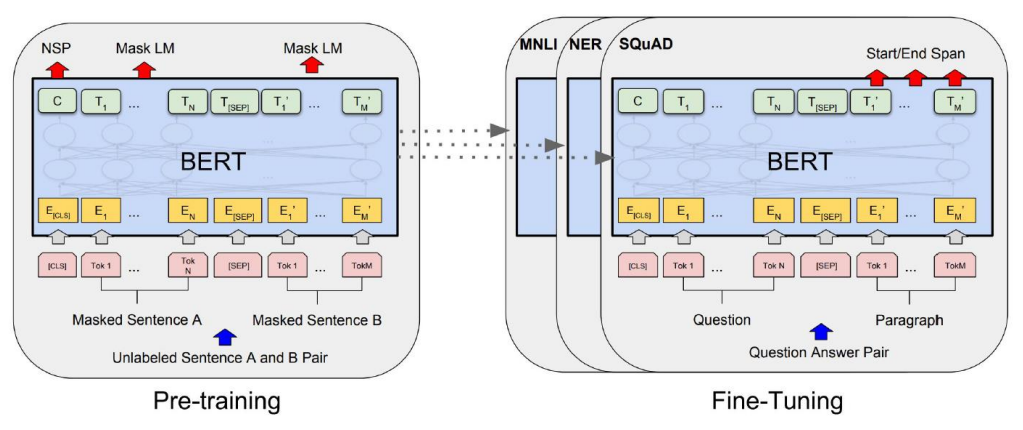

BERT vs. GPT
| GPT | BERT | |
| Training-data size | Trained on BookCorpus(800M words) | Trained on BookeCorpus + Wikipedia (2,500M words) |
| Training special tokens | <S>, <E>, $ ··· | [SEP], [CLS], sentence embedding during pre-training (Segment Embedding) |
| Batch size | 32,000 words | 128,000 words * 일반적으로 Batch size가 크면 성능 향상 (But, GPU memory ↑) |
| Task-specific fine-tuning | All fine-tuning experiments에서 똑같은 learning rate(5e-5) 사용 |
Task-specific fine-tuning learning rate |
BERT의 task별 fine-tuning results (by BERT, NAACL´19)

Machine Reading Comprehension (MRC) Question Answering
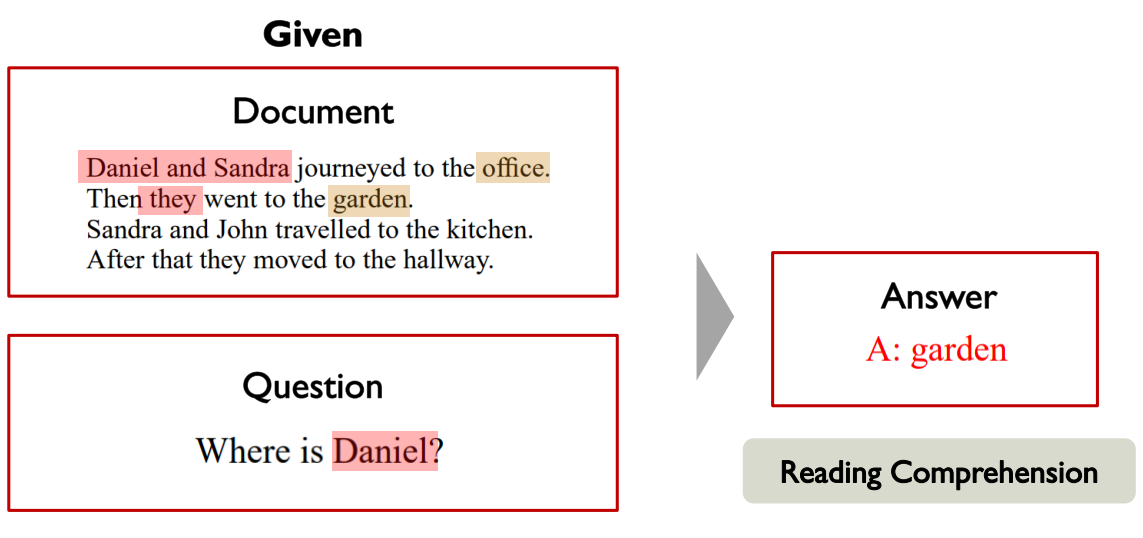
지문 Encoder + 질문 Encoder 必
BERT: On SQuAD 1.1

Only new paramters: Start vector and End vector


BERT: On SQuAD 2.0
- Token 0 ([CLS])로 "no answer" logit 표현
- "No answer"은 answer span과 경쟁
- Threshold는 dev set에 의해 optimized

References
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian 2021 Update: I created this brief and highly accessible video i
jalammar.github.io
https://nlp.stanford.edu/seminar/details/jdevlin.pdf
'NLP' 카테고리의 다른 글
| Sequence/Token Classification (0) | 2022.07.06 |
|---|---|
| GPT (0) | 2022.07.05 |
| Sinusoidal Positional Encoding 직접 계산해보기 (0) | 2022.07.01 |
| Transformer (0) | 2022.06.30 |
| Tokenization (0) | 2022.06.28 |



