Sequence/Token Classification
Token: 작은 단위
Sequence: 한 문장
Document: Muti-sentences
NLP Roadmap

Text Classification
(Sequence Classification)

- Classify the entire text → categories
- Extract the entire token representation → 'prototype' representation
E.g., spam classifier, sentiment analysis, article classifier
Token Classification
(Sequence Tagging)
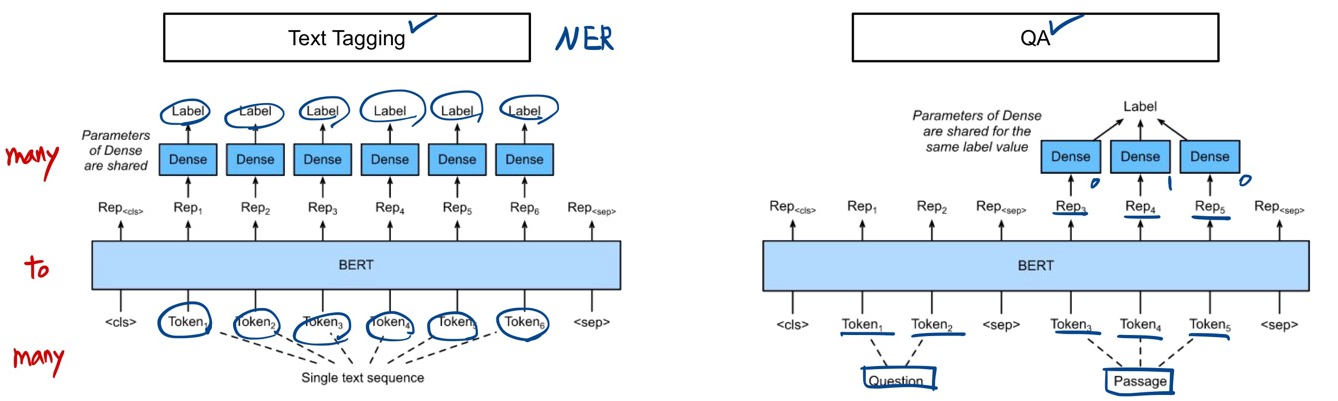
- Classify each token of the text
Named Entity Recognition
(NER)

- Named entity: Real-world object
- Named entities can be viewed as entity instances
(e.g., New York City is an instance of a city)
Named-entity recognition: Locate, Classify anamed entities mentioned in unstructured text → pre-defined categories
(pre-defined categories: person names, organizations, locations, ···)
| Original Sentence | Ground Truth Entity |
| "EU rejects german call to boycott british lamb." | EU-ORG, german-MISC, british-MISC |
NER as BIO tagging
(Token-level prediction)
B - Begin / I - Interior / O - out
Ex1) EU rejects german call to boycott british lamb.
· Process into ['eu', 'reject', '#s', 'german', 'to', 'boycott', 'british', 'lamb', '.']
· Label: ['B-ORG', 'O', 'O', 'B-MISC', 'O', 'O', 'B-MISC', 'O', 'O']
Ex2) Barack Obama was the president of the United States.
· Label: ['B-PER', 'I-RER', 'O', 'O', 'O', 'O', 'O', 'B-MISC', 'I-MISC', 'O']
Machine Reading Comprehension
(MRC)
- Question Answering (Extractive): Context 안에 answer 존재
- Hypothesis: Grount truth answer always in the paragraph (context)

- Input: Context and Question
- Expected Output: Span in the context
- Classifying start, end and others
Question Answering
(QA)


QA example
QA datasets: SQuAD, CoAQ

QA model with pre-trained BERT model
· Question: "Who is the acas director?"
· Answer: "Agnes karin ##gu."

· BERT uses wordpiece tokenization
- Rare words → subwords/pieces
- ##: Delmit tokens that have been split
- "Karin": Common word → maintain
- "Karingu": Rare word → "Karin" and "##gu"
| Input Text | It is supercalifragilisticexpialidocious |
| Split on whitespaces and punctuation | it / is / supercalifragilisticexpialidocious |
| WordPiece tokenization | it / is / super / cali / fra / gil / istic / ex / pia / lido / cious |
Long term dependency in QA

- Model needs to be sufficiently aware of distant tokens

Retrieval
(Document에서 적절한 source text만 extract)

- Search most relevant documents in repsonse to a query
· Reader - Gives the selected documents a closer look by passing them through a pre-trained QA language model
· Model - Return the text passages that it deems most likely to answer the query


Sparse Retriever
(word의 빈도 수 기반)

- Bag Of Words (BOW): Word가 각각 독립 가정
- TF-IDF: Word의 frequency 기반
Dense Retriever

- Query: Question
- Passage: Document
Dense Retriver Visualization

Metrics
Confusion Matrix


- Accuracy: Dataset이 unbalanced 하면 measure 효율 ↓
- Precision: Positive predictive value
- Recall: Sensitivity or True positive rate
- F1 score: Both precision and recall ↑일 때 high

ROC curves

· TP rate: Plotted on the Y axis
· FP rate: Plotted on the X axis
- Relative trade-offs between benefits (true positives) and costs (false positives)
| F1 score | ROC curves |
| - Predict score의 비율값 - Threshold 설정 必 |
- Predicted class |
Area under and ROC Curve
(AUC)
- Calculate the area under the ROC curve
- Portion of the area ot the unit sparse → 0 ~ 1.0 value
- Less than 0.5 → No realistic classifier

References
Question Answering System with BERT
This article explains, What is BERT, the Advantages of BERT, and how to create a QA system with fine-tuned BERT.
medium.com
15.6. Fine-Tuning BERT for Sequence-Level and Token-Level Applications — Dive into Deep Learning 0.17.5 documentation
d2l.ai
A Fast WordPiece Tokenization System
Posted by Xinying Song, Staff Software Engineer and Denny Zhou, Senior Staff Research Scientist, Google Research Tokenization is a funda...
ai.googleblog.com
Understanding Semantic Search and Question Answering | deepset
In this article, we explain key concepts and terminology of semantic (or 'neural') search and question answering systems.
www.deepset.ai
CiteSeerX — Unknown file type
No document with DOI "10.1.1.10.9777" The supplied document identifier does not match any document in our repository.
citeseerx.ist.psu.edu
'NLP' 카테고리의 다른 글
| Neural Machine Translation (0) | 2022.07.08 |
|---|---|
| Text Generation (0) | 2022.07.07 |
| GPT (0) | 2022.07.05 |
| BERT (0) | 2022.07.01 |
| Sinusoidal Positional Encoding 직접 계산해보기 (0) | 2022.07.01 |



