Text Generation
Text Generation
(Natural Language Generation: NLG)
Given some inputs, a model generates new texts
Text Generation Applications
· Machine Translation
· Open-ended Genration (자유 생성)

· Documnet Summarization

· Dialogue System

· Question & Answering / Entity Retrival
Formulation of Text Generation
| Text classification | Text Generation |
| Only a few prediciton | Large probability space of text generation (vocab_size=10000, sequence_lenght=30 → the number of cases for possible text = 10000^30) |
| MLE with Cross-Entropy | Conditional probability with chain rule |

· X: Source Text, Y: Target Text (to be genrated)
(In Machine Translation, X: Source, Y: Target,
In Summarization, X: Long paragraph, Y: Summary)
In Seq2Seq model,

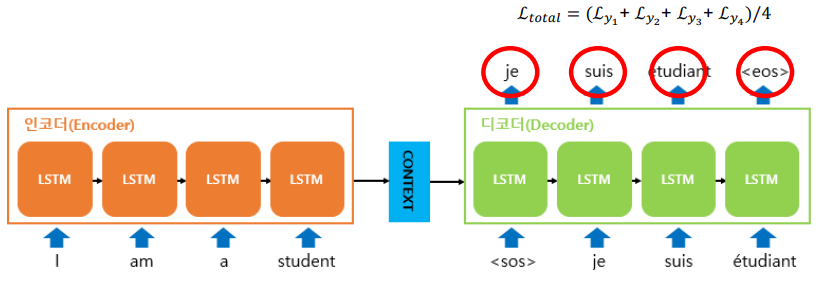
Teacher forcing
"How to provide input words to a decoder?"

With Teacher forcing
- Groud-truth target word가 decoder의 next input으로 투입
- 이전 timestep의 prediction은 다음 prediction에 영향을 끼치지 않음

Without Teacher forcing
- Generated word가 decoder의 next input으로 투입
- 이전 timestep의 prediction이 다음 prediction에 영향을 끼침

Pros of Teacher forcing: Fast, stable, efficient training
Cons of Teacher forcing: Exposure Bias(Generation model test시, groud-truth word가 없음)
→ Train과 test의 groud-truth 유무로 인한 discrependency가 model 성능 저하
Scheduled Sampling
Train 초반에 Teacher forcing 시행 후, 점차 제거

cf) 다만, 최근 model에서는 매번 teacher forcing을 시행하는 추세 (by GPU 병렬처리)
Decoding Strategy
Train된 model로 text generate하는 과정
Greedy Decoding

Most probable word (argmax)를 generate

→ Optimal한 generation은 아님
Beam Search
Decoder의 각 step에서 K개의 most probable partial sequence 선택
If beam size = 2:

Pros of Beam search: High recall value (TP / (TP + FN))
Cons of Beam search: Generate dull, reptitive sequence


Penalized sampling

Sampling-based Decoding Strategy
"Human do not always select the words with the highest probability."
→ More diverse, surprising, not boring texts generate 필요
→ Randomness 요소 추가
→ Random Sampling, Top-k Sampling, Top-p Sampling (or nucleus sampling)
Random Sampling

Con of Random Sampling: Very low probability word가 선택될 수도 있음

Random Sampling with Temperature
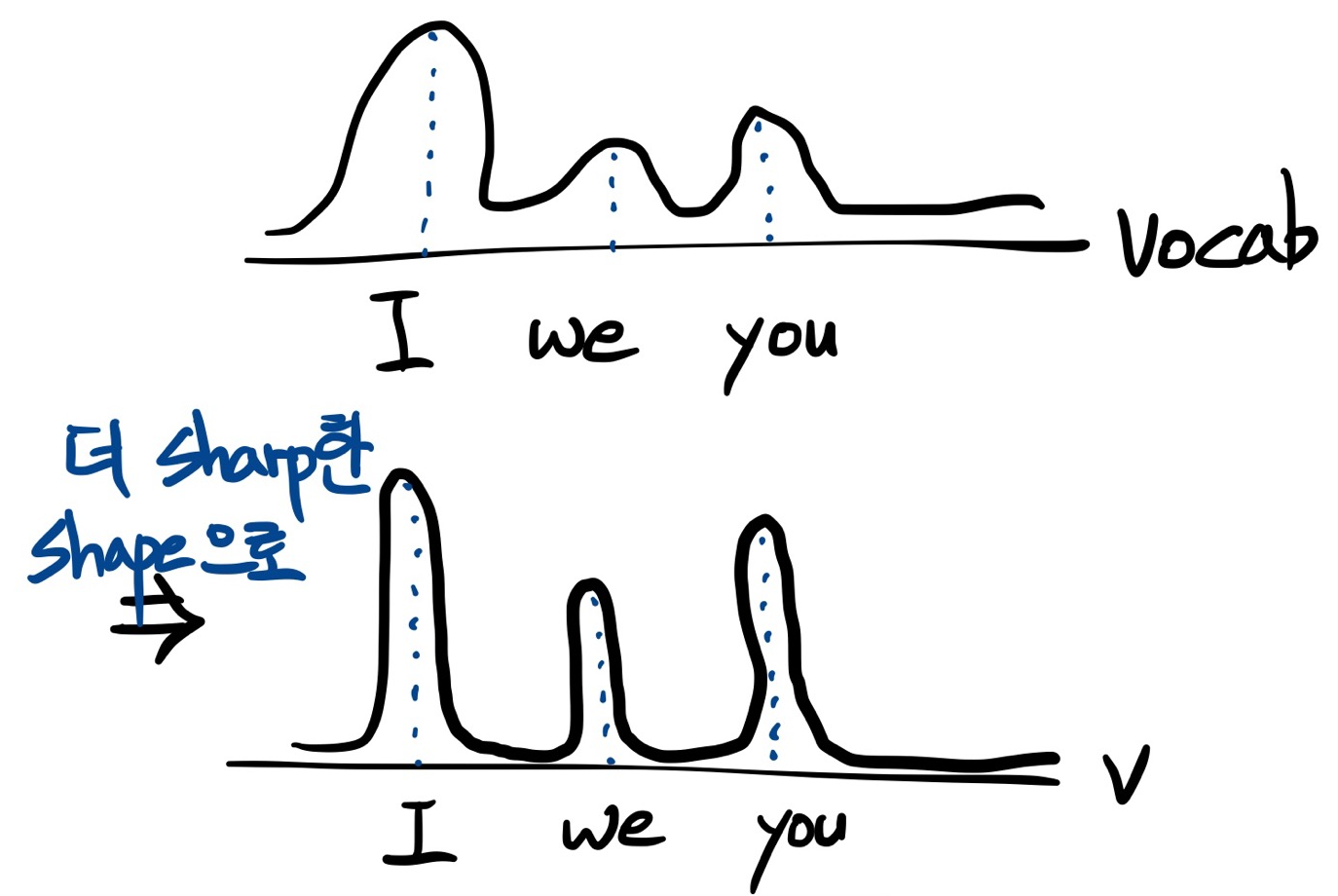
Adjust the probability flat or sharp

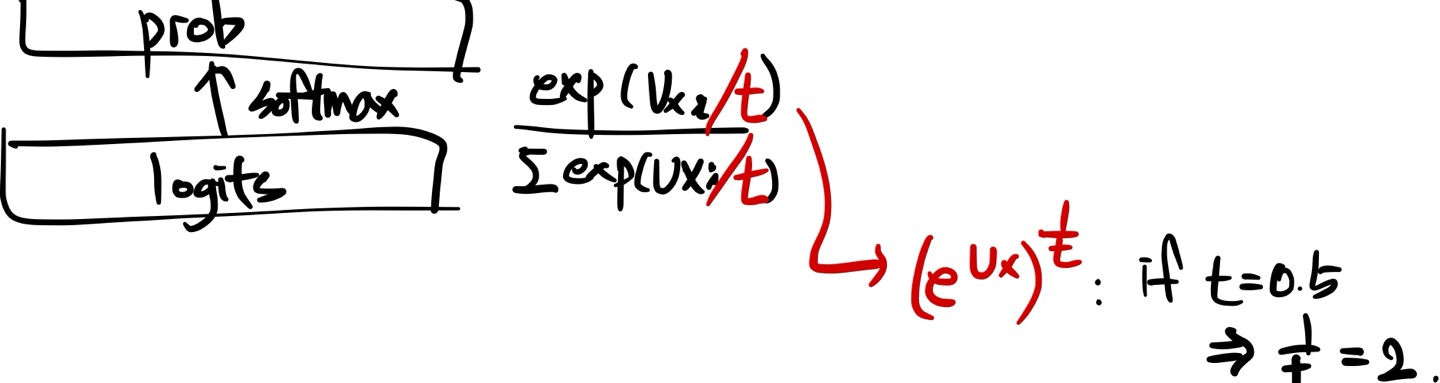


- t < 1: 더 sharp한 graph (seqeunce optimize ↑)
- t > 1: 더 flat한 graph (seqeunce diversity ↑)
- t→0: Greedy Decoding
- t→∞: Uniform Sampling
Top-K Sampling
K개의 most likely word를 sampling

Con of Tok-K Sampling: Fixed된 K개를 sampling하는 것은 별로 비효율적

Top-P Sampling (Nucleus Sampling)
Probability P를 설정하여 가장 possible한 set of words sampling

Evaluation Metric in NLG
NLG의 정량적 평가는 최고 난제
Common approach: Generated된 text와 answer text간의 similarity 비교

Word-level Similarity
- BLEU: Machine Translation에서 많이 사용, n-gram 기반
- ROUGE
- METEOR
Embedding Similarity
- Word Average / Extrema / Greedy
- BERTScore
Perplexity (PPL)
Target sentence가 존재하지 않을 때,

(Generated text가 아닌!!) Generation model의 performance를 측정
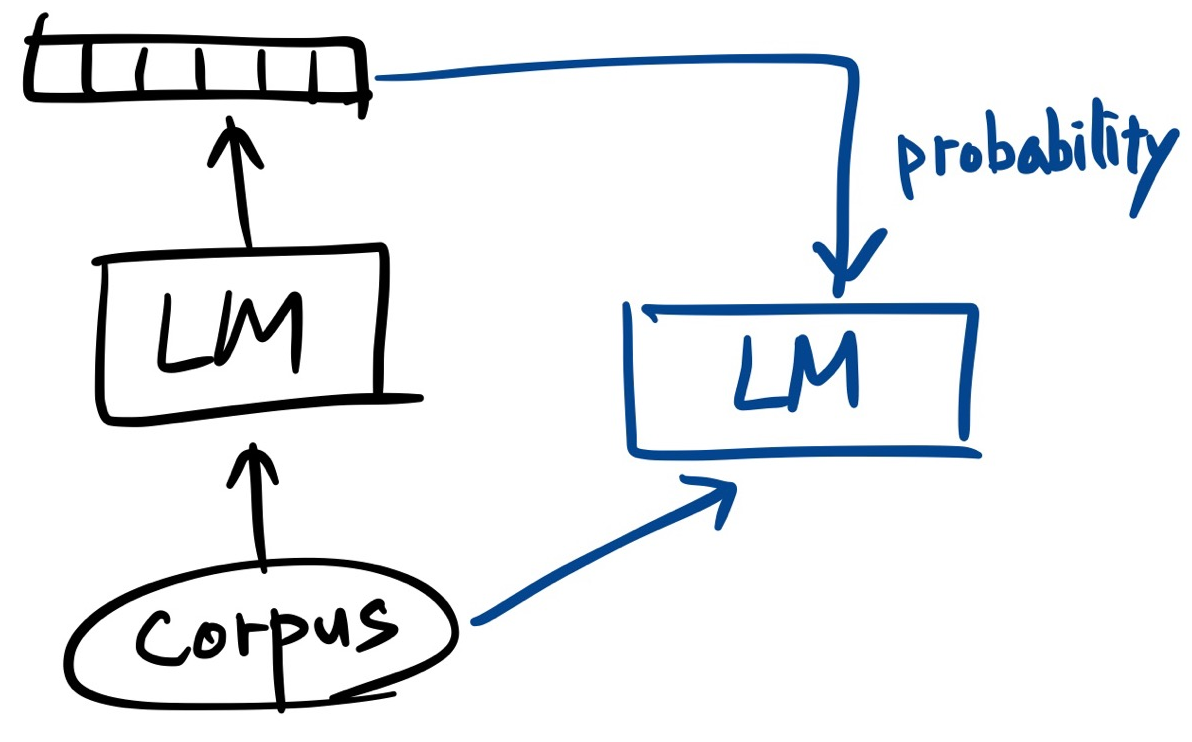
- Model이 얼마나 text를 predict할수 있는지 reciprocal
- PPL↓ model is better
(일종의 loss 값이기 때문에..!)
References
CS224n(http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture15-nlg.pdf)
https://ai-information.blogspot.com/2019/03/scheduled-sampling.html
Scheduled sampling
AI에 관련된 논문과 지식을 포스팅한 블로그입니다.
ai-information.blogspot.com
[1908.04319] Neural Text Generation with Unlikelihood Training (arxiv.org)
[1904.09751] The Curious Case of Neural Text Degeneration (arxiv.org)
The Curious Case of Neural Text Degeneration
Despite considerable advancements with deep neural language models, the enigma of neural text degeneration persists when these models are tested as text generators. The counter-intuitive empirical observation is that even though the use of likelihood as tr
arxiv.org
[1704.04368] Get To The Point: Summarization with Pointer-Generator Networks (arxiv.org)
Get To The Point: Summarization with Pointer-Generator Networks
Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: th
arxiv.org
[1909.05858] CTRL: A Conditional Transformer Language Model for Controllable Generation (arxiv.org)
CTRL: A Conditional Transformer Language Model for Controllable Generation
Large-scale language models show promising text generation capabilities, but users cannot easily control particular aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model, trained to condition on con
arxiv.org
Decoding Strategies that You Need to Know for Response Generation
Techniques to make your generative models better
towardsdatascience.com
'NLP' 카테고리의 다른 글
| Neural Machine Translation (0) | 2022.07.08 |
|---|---|
| Sequence/Token Classification (0) | 2022.07.06 |
| GPT (0) | 2022.07.05 |
| BERT (0) | 2022.07.01 |
| Sinusoidal Positional Encoding 직접 계산해보기 (0) | 2022.07.01 |



