*사용된 모든 영문 image의 출처는 cs231n 강의 자료입니다.*
<Attention Models>
1. Image Captioning
2. Image Captioning with Attention
3. Visual Question Anwsering
Image Captioning
Language model
- P(next word | previous word)

Image Captioning
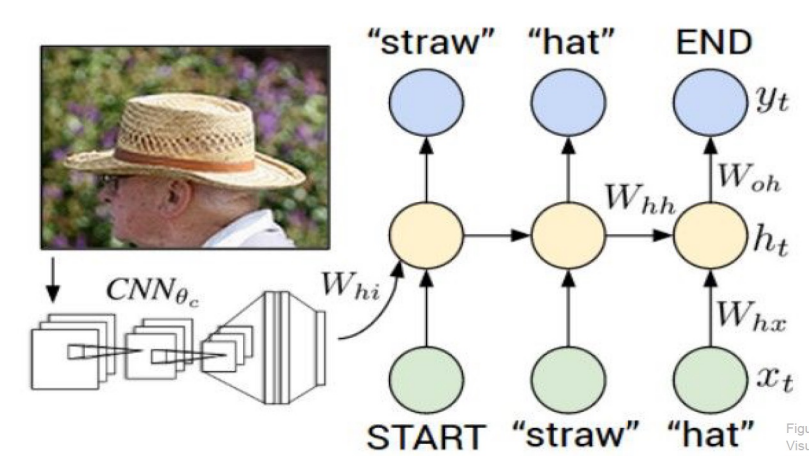
Explain Images with Multimodal Recurrent Networks, Mao et al.



- CNN의 FC layer에서 vector 추출
- RNN의 hidden state vector로 전달 (Wih * v)
- tanh(Wxh * x + Whh * h) → tanh(Wxh * x + Whh * h + Wih * v)
- Whole image의 전체적인 맥락 파악 (context vector)
- But, sentence가 길어지면 train 하락 → Attention model으로 해결

- CNN의 FC layer에서 context vector 추출 → Features: D
- RNN Hidden state h0의 input 전달
Image Captioning with Attention
Image captioning with Attention

- RNN looks at different parts of the image at each timestep
- CNN의 Convolution layer에서 vector 추출 (Vanilla Image Captioning은 FC layer)

- h0에서 location 확률 분포 vector a1 추출
- Feature map으로 weighted combination 후 weighted feature vector z1 추출
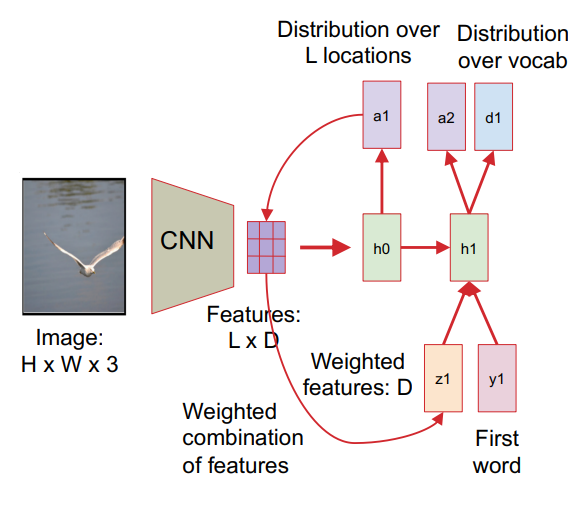
h1의 input:
- First word vector y1
- Weighted feature vector z1
- 이전 hidden state vector h0


| Soft attention | Hard attention |
| · 모든 location 고려 · 빠르고 쉽게 Image Captioning 적용 가능 |
· 가장 높은 확률의 element만 고려 · Backpropagtion 대신 강화학습 train 사용 · Soft attention에 비해 연산량↓ 정확도↑ |

Vanilla Image Captioning vs. Image Captioning with Attention

Viusal Question Anwsering

Visual Question Answering: RNN with Attention

Attention Mechanism의 또 다른 장점?

Attention Weight Map을 통해 각 word의 attention weight를 파악할 수 있다 !
'Deep Learning' 카테고리의 다른 글
| Self-Supervised Learning (0) | 2022.06.14 |
|---|---|
| Generative Adversarial Networks (0) | 2022.06.13 |
| Convolution 연산 시, channel 수 / filter 수와 parameter 수 관계 정리 (0) | 2022.06.09 |
| Recurrent Neural Networks (0) | 2022.06.08 |
| CNN Architectures (0) | 2022.06.07 |



