*사용된 모든 영문 image의 출처는 cs231n 강의 자료입니다.*
<Generative Adversarial Networks>
1. GAN introduction
2. GAN
3. Variants of GAN
GAN introduction
Branches of ML

Supervised Learning

"how to classify"
Unsupervised Learning
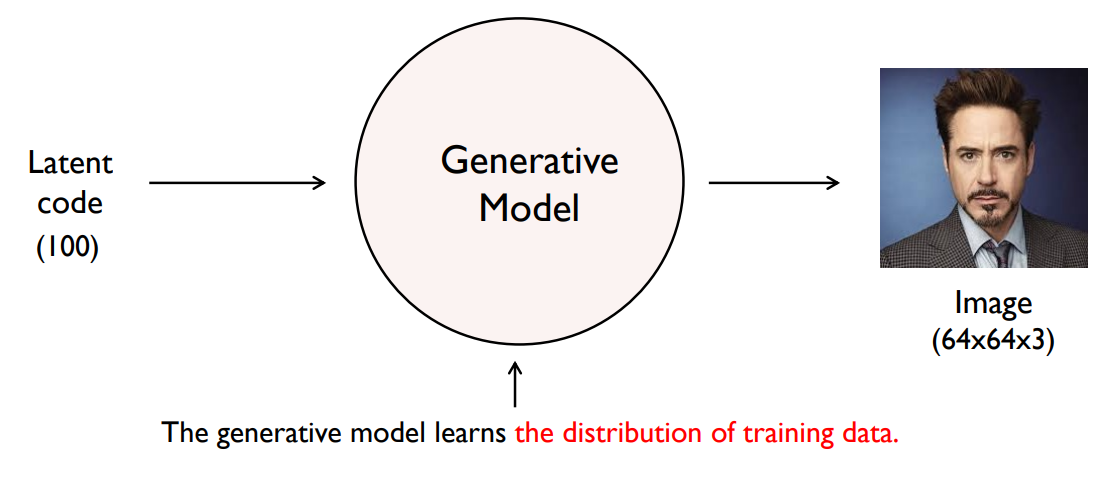
"Learn the distribution of training data"
Probability distribution
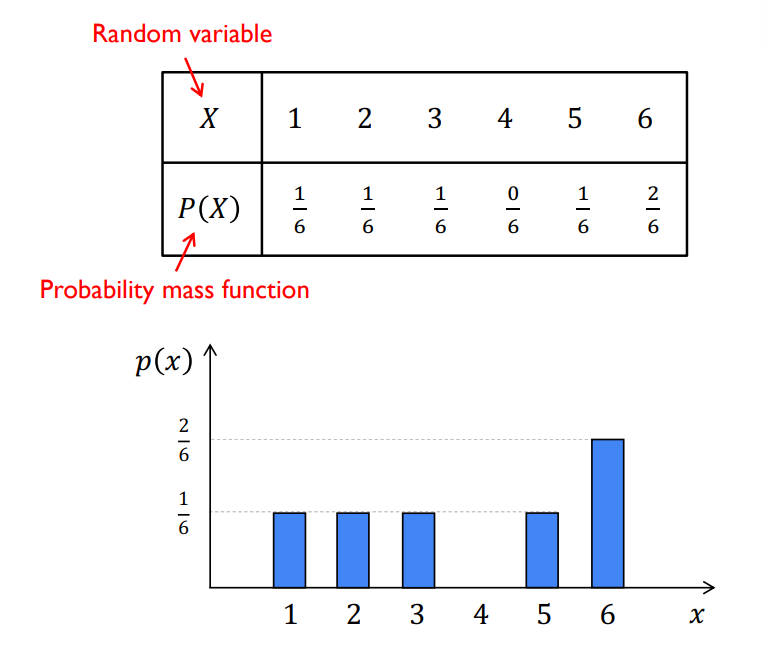
- Probability variable이 특정한 값을 가질 확률을 나타내는 함수
Discrete probability distribution
Probability variable X의 개수를 정확히 셀 수 있을 때의 함수
Continuous probability distribution
Probability variable X의 개수를 정확히 셀 수 없을 때의 함수 (probility density function으로 표현)

Kernel density estimation

Probability distribution in Image data
- Image data는 다차원 feature 공간의 한 점으로 표현
- Image의 distrbution을 근사하는 model train
- Multivariate probability distribution


Generative Models
- 실존하지 않지만 있을 법한 image 생성
- A statistical model of the joint probability distribution
- An architecture to generate new data instances

→ Original image들의 distribution을 잘 modeling하는 게 목표 !!

→ 시간이 지나면서 model이 original data의 distribution을 train

- Pmodel = Distribution of images generated by the model
- Pdata = Distribution of actual images
→ Pmodel(x) approximates Pdata(x)
GAN
Generative Adversarial Network

- Generator와 Discriminator 두 network를 활용
Objective Function of GAN

- Discriminator should Maximize V(D, G):
Real image → 1, Fake image → 0
- Generator should Minimize V(D, G):
Generate된 Fake image가 Discriminator에 의해 1 이 나오게 train
Ez~pz(z)[log(1 - D(G(z)))]만 Objective Function으로 사용
Discriminator:
D(x) = probability: a sample came from the real distribution (Real: 1 ~ Fake: 0) # 확률값
Generator:
G(z) = new data instance

- Sample x: From real data distribution
- Sample latent code z: from Gaussian distribution
- Ex~p_data(x)[logD(x)]: 원본 data distribution에서 sample x를 뽑아 logD(x)의 기대값 계산
→ Maximum when D(x) = 1
- Ez~p_z(z)[log(1 - D(G(z)))]: noise distribution에서 sample z를 뽑아 log(1 - D(G(z)))의 기대값 계산
→ Maximum when D(G(z)) = 0

Goal of GAN
- Pg → Pdata, D(G(z)) → 1/2
G(z)의 fake image를 Discriminator가 더 이상 구분 불가
- Pg에 noise 추가 시, Pdata와 다른 new data instance 생성
PyTorch Implementation (Toy GAN)

import torch
import torch.nn as nn
D = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid())
G = nn.Sequential(
nn.Linear(100, 128),
nn.ReLU(),
nn.Linear(128, 784),
nn.Tanh())
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.01)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.01)- Use MNIST data set: 28 x 28 x 1 → 784 input dimension
- Use BCE loss
- Generator의 마지막 Tanh function: -1 ~ 1 → 0 ~ 255 pixel (다른 function 쓰더라도 pixel 범위만 mapping시키면 된다!)
# Assume x be real image of shape (batch_size, 784)
# Assume z be random noise of shape (batch_size, 100)
While True:
# Train D
loss = criterion(D(x), 1) + criterion(D(G(z)), 0)
loss.backward()
d_optimizer.step()
# Train G
loss = criterion(D(G(z)), 1)
loss.backward()
g_optimizer.step()- Train Discriminator loss: min((D(x) -1)² + D(G(z) - 0)²)
- Train Generator loss: min(D(G(z) - 1)²)
- 2 optimizer 사용 이유?
→ Discriminator와 Generator의 학습 격차에 따른 오류 방지
(일반적으로 Generator는 new instance를 생성해야하기 때문에 초기에 Discriminator보다 loss 줄어드는 속도가 느림)
Visual of Experiment

- Not cherry-picked (random)
- Not memorized the training set → 노란색 box안 data가 마지막 data와 조금 다르다!
- Competitive with the better generative models
- Images represent sharp
Variants of GAN
Deep convolution layer

Deep Convolution GAN (DCGAN), 2015

- Use Deep Convolution network
Discriminator
- Use convolution, Leaky ReLU
- Leaky ReLU: (음수값 x 0.01)로 음수 값 일부 반영

Generator
- Use deconvolution, ReLU
- No pooling layer (Deep Convolution layer 사용)
- Use Batch Normalization
- Adam optimizer(lr=0.0002, beta1 = 0.5, beta2 = 0.999)
'Deep Learning' 카테고리의 다른 글
| GAN generator Loss function (0) | 2022.06.15 |
|---|---|
| Self-Supervised Learning (0) | 2022.06.14 |
| Attention Models (0) | 2022.06.12 |
| Convolution 연산 시, channel 수 / filter 수와 parameter 수 관계 정리 (0) | 2022.06.09 |
| Recurrent Neural Networks (0) | 2022.06.08 |



